随机微积分导论
Brian Keng
通过几条不同的路径,我又一次掉进了一个“兔子洞”,最终来到了这篇文章的主题。第一条路径是我最近专注的某个机器学习课题,该课题使用了一些来自物理学的概念,自然而然地引导我走向了随机微积分(stochastic calculus)。第二条路径是我在量化金融领域的一些工作项目——这是随机微积分的主要应用领域之一。天真地以为我可以写一篇简短的文章来满足我的好奇心——结果完全不是这么回事!最终成了一篇超长文章。
这篇文章的主题是随机微积分,它是普通微积分对随机过程(stochastic processes)的一种扩展。虽然一开始并不明显,但要真正理解其中的一些核心思想,其背后的严谨性要求我们回到以测度论(measure theory)为基础的概率论定义上,因此文章从这一背景知识开始。随后我会很快过渡到随机过程、Wiener过程(Wiener process)、一种特定形式的随机微积分——伊藤微积分(Itô calculus),并最终以几个应用案例收尾。
一如既往,我尝试在直觉和严谨性之间取得平衡,尤其是在严谨性能够帮助构建直觉的时候,同时还会附上一些简单的例子。这个话题既深且广,希望你喜欢这篇我的消化整理笔记。
原文链接:https://bjlkeng.io/posts/an-introduction-to-stochastic-calculus/
翻译:droggeljug Github页面
研究动机
许多物理现象(以及金融现象)都可以建模为一个随机过程(stochastic process),并用随机微分方程(stochastic differential equation)来描述。然而,这两个内容在大多数概率论或微积分的入门课程中通常不会涉及。
从随机过程开始,最直观的理解方式是:它是由一组按时间索引的随机变量组成的集合。换句话说,与其在每个时刻 上都有一个确定的数值,我们现在在每个时刻上有一个随机变量(这些变量之间通常有某种关联或共同属性)。表面上看这似乎很简单,但复杂性在于当我们令 是连续时间变量时,问题就会变得更加棘手——我们稍后会详细看到。
在连续时间上的随机微分方程,是建模许多不同现象的非常自然的方式。一种常见的随机微分方程称为Langevin 方程(Langevin equation),它被用来描述多种类型的随机现象:
其中 是一个随机过程,、 是 和时间 的函数, 是噪声项。这个噪声项是使该微分方程“特殊”的关键,它引入了一种特别类型的随机性。虽然这只是一个示例,但它具有许多在其他随机微积分应用中也会出现的典型特征。
从直觉上来说,噪声项 表示“随机波动”,例如粒子在流体中与其他分子的随机碰撞,或股票价格的随机波动。为了精确定义这种“随机波动”,我们需要首先指定其某些性质,比如其时间相关函数(time correlation function):
由于这些波动是随机的,因此 应该是 的递减函数,不应具有持续的影响。但这个定义很容易变得复杂,因此我们通常会采用更简洁的抽象模型来描述这些系统。
一种常见的简化假设是:这些随机波动在时间上完全不相关。如果我们关注的时间尺度远大于这些波动的时间尺度,这个假设是合理的。在这个前提下,我们有:
其中 是常数, 是狄拉克 δ 函数(Dirac delta function)。这意味着即使在无穷小时间尺度上,随机波动也是完全不相关的。另一个对应的假设是:在每个时间点 ,随机变量 是一个均值为零的高斯分布。
从某种角度看, 简化了问题;但从另一些角度来看,它也使问题更加复杂。首先需要注意的是, 是一个理论构造——现实中并不存在一个真正的随机过程能完全满足其性质。从式 (1.3) 可以看出,我们使用了理论上的狄拉克 δ 函数。这也意味着 的方差是无穷大(即 )。该构造具有所有频率下都为常数的功率谱密度(power spectral density),即无限带宽信号(参见 Wikipedia),这在物理上是不可实现的。
这个定义还带来另一个后果,即 在所有时间点上都是不连续的。在 处的取值可能与稍后一点 的取值完全不同。这种性质使得诸如积分这样的基本运算变得非常困难。
回到我们在式 (1.1) 中的随机微分方程,我们可以两边同时乘以 并对两边积分,希望能得到:
右边的第一个积分是标准积分,一般可以用常规微积分工具求解。而第二个含有 的积分正是我们遇到的难题。正是这一问题促使数学家们发展出一个新的数学分支——随机微积分,也就是本文的主题。
随机过程
概率空间与随机变量(Probability Spaces & Random Variables)
注:如果你已经熟悉测度论下的概率定义,可以跳过本节。
我们现在深入探讨测度论下的概率定义,尝试在保持一定数学严谨性的前提下提供一些直觉理解。首先,我们来看“概率空间”的定义: 。 这和你在第一门概率课里学到的概念类似,只不过换上了更精确的数学形式。
- 是样本空间(sample space),定义了实验中所有可能的结果。
- 在有限样本空间中, 的任何子集都被称为一个事件(event)。直觉上,事件就是我们想要对其测量概率的“对象群组”,比如 中的单个元素、元素的并集、甚至是空集。
然而,当样本空间是某些类型的无限集合(比如实数轴)时,这种事件定义方式会失效。因此我们需要用事件空间 (其中 表示幂集)来更精确地定义事件,事件空间的构造使用了所谓的 -代数(sigma-algebra):
-代数的定义:
设 为非空集合, 是其子集的集合。我们称 为 -代数,如果满足:
- 空集 属于 ;
- 若 ,则其补集 ;
- 若 ,则它们的可数并集 。
-代数中的元素被称为可测集合(measurable sets),而 被称为可测空间(measurable space)。
我们希望事件空间 是一个 -代数,并与 一起构成一个可测空间。虽然这听起来复杂,但它确保了我们用于定义事件的 的子集具有我们期望的“良好”概率特性。
直观上,可测空间的作用是给“体积”或“大小”的概念提供一个一致的分割方式(类似用不重叠的积木构造出一个房子)。这在面对非可数集合时是必要的;而对于有限集合,一般使用幂集 就足够了。
然后是概率空间的最后一个组成部分:
概率测度(probability measure) 是一个函数,定义在事件空间 上,满足以下性质:
- 将事件映射到单位区间 ;
- 空集映射为 ,全集 映射为 ;
- 满足可数可加性(countable additivity):对于两两不交的事件集合 ,
这三条就是我们在概率论中最基础的公理,这里只是把它们更加形式化了,尤其是最后一条,它通常没有在初学阶段以“无限集合”形式出现。
我们再来看“体积”类比下的解释:概率测度就相当于把“体积的块”映射到 ,但要保持一致性。得益于事件空间是 -代数,加上等式 (2.1) 的条件,我们就能确保无论如何组合这些“体积块”,概率测度都是一致的。对于有限样本空间,这些功能是显然的;但在连续样本空间中,就需要严谨定义。
最后,在给定的概率空间 中,我们定义:
随机变量(random variable) 1是一个可测函数(measurable function)
其中:
- 的值域 必须构成一个可测空间 ,即 是 上的 -代数;
- 对于任意 ,其原像集合:
也就是说, 的取值集合必须能被映射回原始事件空间中的某个事件,使得我们可以用 对其进行概率计算。
因此,对于任意 ,我们可以使用:
这个定义确保了我们可以把样本空间中那些本来没有“数值”意义的事件(例如“正面”或“反面”)映射为实数,用于计算期望、方差等量。
对于很多概率应用,上述内容可能“过于严谨”,大多数概率实践者只用得上一阶定义。但对于随机微积分而言,这些定义让我们有能力处理不可数的无限情况,是深入理解的重要基础。
例 1:样本空间、事件、概率测度与随机变量
(摘自维基百科)
假设我们有一副标准的52张扑克牌(不含大小王),实验为从这组牌中随机抽取一张。此时:
- 样本空间 是包含全部 52 张牌的集合;
- 事件 是 的任意子集,即事件空间 ,即 的幂集。
这意味着事件可以是:
- “同时是红色和黑色的牌”(0 个元素,空集)
- “红桃5”(1 个元素)
- “任意一张国王”(4 个元素)
- “任意一张人头牌(J、Q、K)”(12 个元素)
- “任意一张牌”(52 个元素,全集)
当每张牌被抽到的概率相同,我们可以为事件 定义一个概率测度:
我们还可以定义一个随机变量 为:
这个随机变量是一个从样本空间 到实数子集 的映射。我们可以使用公式 2.3 来计算对应的概率,例如 的概率为:
这个随机变量所蕴含的 -代数 可以表示为 。 这表明我们只需关心与 的取值相关的事件集合(这里是“红色或非红色”),这些集合构成一个满足 -代数性质的子集。
概率论的两个学习阶段
(灵感来源:[1] 第一章笔记)
概率论的学习通常分为两个阶段:
第一阶段 聚焦于离散随机变量(具有概率质量函数)和连续随机变量(具有密度函数)。在这一阶段中,我们学习如何从这些变量中计算期望、方差、条件概率等基本量,掌握一些标准分布的性质,并了解如变量变换等技巧。
这一阶段的知识已足以应对大多数标准应用,从基本的统计检验到似然函数计算。
第二阶段 则深入到以测度论为基础的严谨定义中。在该框架下,随机变量被视为从样本空间 映射到实数子集 的函数。样本空间中某些子集称为事件,所有事件组成 -代数 。 中的每个集合 都对应一个由概率测度 赋予的概率 。
这一定义优雅地统一了离散与连续情形,同时也揭示了第一阶段中许多定理背后的细节。 例如:随机变量不等于分布——同一个随机变量可根据不同的概率测度拥有不同的分布。又如,并非所有分布都拥有密度函数(尽管我们常见的多数分布都有)。正如应用数学中的许多情况一样,这种严谨定义在大多数实际问题中不是必需的,直到你遇到了极端情况(corner case)。同时,由于学习成本较高,多数人(包括本文作者)对其掌握到“令人满意的程度”即可。
-
我这里刻意省略了对 勒贝格积分(Lebesgue integrals)以及其他一些内容的提及,以避免使这个话题变得过于复杂。
它们在数学上确实非常重要,特别是在处理需要对一个集合上进行积分的随机变量时,是必不可少的工具。 ↩
随机过程(Stochastic Processes)
这是来自 [2] 的一个随机过程的正式定义:
假设 是一个概率空间, 是一个具有无限基数的集合。进一步假设对于每一个 ,都有一个定义在 上的随机变量 。
定义函数 ,其映射为 ,这个函数被称为一个以 为指标集的随机过程,记作:
这听起来很复杂!我们来分步骤直观解释这个定义。我们在上一小节已经介绍了概率空间和随机变量。
随机过程的第一层含义是:我们有一组用某个集合 编号的随机变量。通常 是一个全序集合,例如实数的子集(如 )或自然数(如 ),对应于连续时间或离散时间。
接下来我们关注每个随机变量所依赖的概率空间 。关键在于样本空间中的元素 是一个无限序列,对应于在 的每个时刻执行一次实验。(注意:由于是无限个实验,否则这只是一个随机向量。)
例如,从 到 每次掷硬币,将产生一个具体的无限序列 。 每个随机变量 都是从这个无限实验序列中提取某些信息并映射到实数子集的函数 。 需要注意的是,这种通用定义中并没有显式包含“时间方向”的概念,因此可以包含对“未来”的依赖。为了包含通常意义下的时间因果性,我们还需引入“适应性过程(adapted process)”等额外概念(后文会介绍)。
从另一视角,我们可以将随机过程看作关于时间 和样本 的联合函数 。 对于某一次具体实验结果 ,我们就得到了一个样本路径函数 ,这是一个确定性的函数。但在多数情形下,我们习惯使用集合形式的记法来表示一个时序上的随机变量序列 。 有时也用简记形式 来表示时刻 上的随机变量或整个随机过程。
随机过程可以依据值域类型与指标集类型分类如下:
-
离散值/连续值过程(Discrete/Continuous Value Process):当每个 的取值属于一个可数集合(例如自然数的子集)时,称该过程为离散值过程;否则为连续值过程。
-
离散时间/连续时间过程(Discrete/Continuous Time Process):当指标集 为一个可数集合时,称该过程为离散时间过程;否则为连续时间过程。
通常情况下,连续时间过程的分析更为复杂,而本文后续章节将主要聚焦于此。下面两个离散时间过程示例将帮助我们更好地从形式定义过渡到具体情形的直觉理解。
例 2: Bernoulli 过程
最简单的随机过程之一是 Bernoulli 过程,它是一个离散取值、离散时间的过程。其核心思想是在每一个时间点进行一次独立同分布的伯努利试验(可类比为抛硬币)。
更正式地说,我们的样本空间为: 表示由“正面(H)”与“反面(T)”构成的无限序列集合。
事件空间与概率测度的精确定义较为复杂,这部分内容将在附录 A 中详细讨论。现在,给定一次无限投掷的结果 ,我们可以定义如下的随机变量:
其中, 是一次实验结果序列,而每个 表示第 次投掷的结果。
对于任意 ,我们有 , 且 , 表示抛出“正面”的概率为常数 ,该概率在整个过程中保持不变。
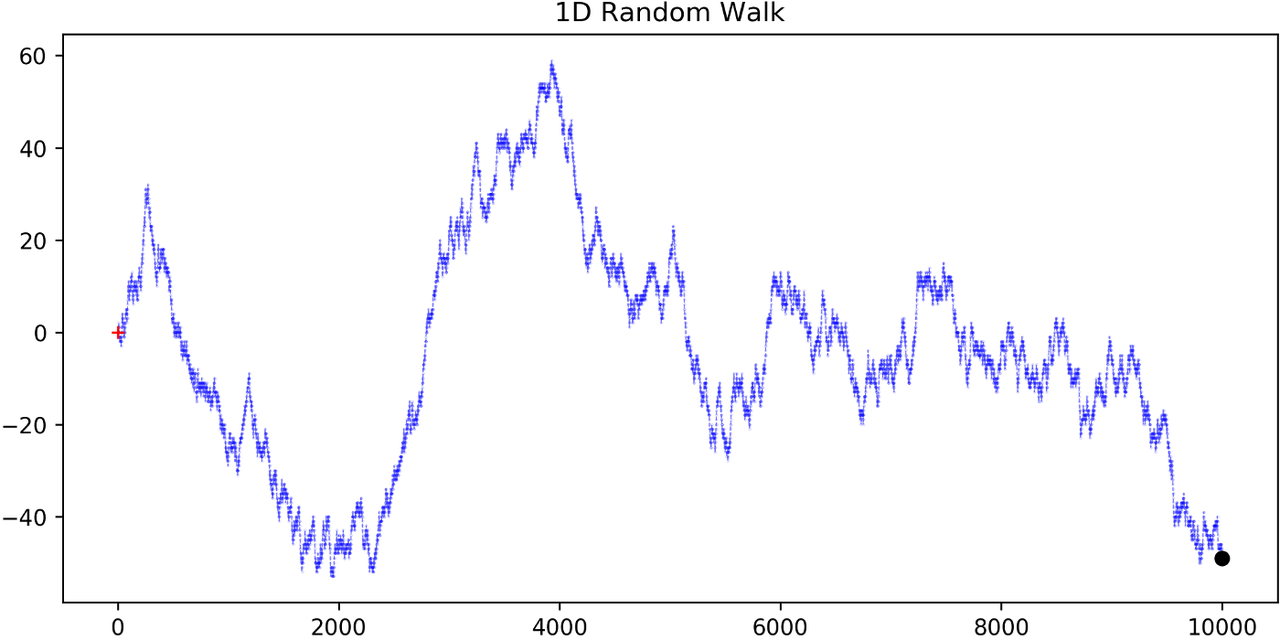
例 3: 一维对称随机游走
一个最简单的一维对称随机游走,是一种离散值、离散时间的随机过程。你可以把它想象成:从 0 开始,每一步抛一次公平的硬币,若正面则向上移动(+1),否则向下移动(-1)。
图 1: 一维对称随机游走 (图片来源)
该过程可以用上一节的伯努利过程 (令 )来定义:
你会注意到, 在每个时间点的取值,依赖于所有先前的“抛硬币结果” ,这与伯努利过程中每一步只依赖当前时刻不同。
接下来是两个我们将在后面使用的重要结论。
首先,对于任意不重叠的整数区间对 所构成的增量变量,如 是相互独立的。这是因为各个差分段只涉及不重叠的 ,而这些 本身是独立的。
此外,增量的期望值与方差如下:
这意味着,对称随机游走的方差以“每步一步”的速率线性增长。如果从当前位置再走 步,那么对应的方差为 。这一规律在后续我们探讨连续时间扩展时会再次出现。
2.3 自适应过程(Adapted Processes)
请注意,在上一节中我们对随机过程的定义包括了如下形式的随机变量: 。 其中每个 表示一次无限长实验的具体结果(通常是一串无限的抛掷结果序列)。
这一设定隐含着:在某个“时间” ,我们有可能依赖于“未来”的结果,因为定义中允许 依赖于所有的试验结果,包括那些时刻大于 的部分。
然而,在许多实际应用中,我们希望将 明确解释为时间变量,因此我们有必要对随机过程的定义施加限制。
所谓一个自适应的随机过程(adapted stochastic process),是指它不能“预知未来”。
更非正式地说,这意味着对于任意时刻 的变量 ,我们只能依据实验结果的前 项(即 )来确定其值,而不能借助未来的信息。
为了更严格地刻画这一点,我们需要引入几个技术性的定义。
在此前的子章节中,我们已经介绍了由随机变量 所诱导的 -代数 。
现在,设我们有一个事件空间的子集 ,如果 ,那么我们称 是 -可测 (-measurable)的。
这意味着我们可以仅通过 中的信息来描述或“测量”与 有关的所有事件。
基于这一概念,我们可以在事件空间 与索引集合 上引入滤子(filtration)的概念:
滤子(Filtration) 是一组有序的 -代数集合: 。 其中每个 是 的子 -代数,且满足对于任意 有:
换句话说,事件空间 被划分成了一系列按照时间递增的信息集合 ,随着时间推移,我们可以获取的信息越来越多,但不会遗失原有的信息。
这种结构正是对“信息随时间演化”的一种形式化描述,在许多随机过程理论和金融数学中至关重要。
在此基础上,我们可以正式定义自适应过程:
一个随机过程 若满足对任意 , 是 -可测的,则称该过程对滤子 是自适应的(adapted)。
也就是说, 只能依赖于时间 时刻之前或当时所掌握的信息。
这种“可用信息”正是由 编码的。
我们只能在 所描述的事件之上计算与 有关的概率,从而有效限制了信息获取的范围,避免依赖未来信息。
正如随机过程中的许多概念一样,我们需要保持高度的形式化严谨性,以防止出现违反因果性或悖论的情况。
接下来的例子将帮助我们更直观地理解滤子与随机变量之间的关系。
例 4:自适应伯努利过程(Adapted Bernoulli Process)
首先,我们需要为伯努利过程指定一个所适应的滤族(filtration)。借用附录 A 中的定义,我们重述如下两个事件集合:
这两个集合分别定义了所有以“正面(Head)”和“反面(Tail)”开头的无限抛掷序列。我们使用这两个集合来构造第一个子 -代数:
注意到 ,这是由定义决定的。我们也可以看看由随机变量产生的事件:
因此,我们有 。 也就是说,随机变量 所诱导的 -代数与我们构造的 完全一致,意味着 是 -可测的(measurable),这正符合我们对自适应性的要求。
让我们进一步理解其含义。根据式 (2.11),在时间 时刻我们能够度量的事件只有以下几种:空集、全集、首抛为正面的所有序列,以及首抛为反面的所有序列。这对应的概率值只有四种:、、 和 ,刚好是我们期望伯努利变量 能够计算的结果。
但深入来看,这与直觉上的理解还是有区别的。集合 包含的是所有以正面开头的无限序列,而不仅仅是“第一次抛掷是正面”的信息。
请记住,在随机过程中每一个时间索引 所对应的 实际上是作用于整个样本空间 上的函数,而这个样本空间由无限长的序列组成。因此,我们无法仅凭“首项为 H”这样的朴素想法来定义事件集合,而需要使用符合条件的整个序列集合来进行分组和概率测量。这种形式化的定义虽然复杂,但正是为了应对无限样本空间下的严谨性问题。
如果我们继续向后构造更高时间点的滤族,例如:
采用类似方式定义,那么可以发现每一个 都是 -可测的(详见附录 A)。同时,每一个 都包含其前一时刻的 ,即滤族是递增的。
因此,我们可以得出结论:伯努利过程 是适应于滤族 的,正如附录A中定义的那样。
Wiener 过程(Wiener Process)
Wiener 过程(也称为布朗运动)是最被广泛研究的连续时间随机过程之一,它频繁出现在诸如应用数学、量化金融和物理学等多个领域中。正如我们之前所提到的,它具有许多“边界情况”的性质,这些性质使得该过程无法通过简单的方法进行处理,也正是因为这些问题,才催生了随机微积分的发展。值得注意的是,Wiener 过程存在多个等价的定义,而我们将从参考文献 [1] 中给出的一个定义出发,该定义使用了缩放的对称随机游走(scaled symmetric random walk)过程。
缩放对称随机游走(Scaled Symmetric Random Walk)
缩放的对称随机游走是我们在例 3 中所展示的简单随机游走的一种扩展,我们将“加快时间”并“缩小步长”,从而将其扩展到连续时间。更准确地说,对于一个固定的正整数 ,我们定义如下的缩放随机游走过程:
其中 是一个简单的对称随机游走过程,前提是 是一个整数。如果 不是整数,我们则通过线性插值来定义 。
一个直观的理解方式是:公式 2.13 本质上就是一个带缩放因子的普通随机游走。例如, 的第一次整数步长发生在 而不是 。为了调整这种时间压缩的影响,我们对过程施加 的缩放因子(稍后会更详细地讨论其原因)。线性插值的部分本身并不重要,只是我们希望在连续时间中进行操作。下图展示了这一缩放随机游走的可视化结果:
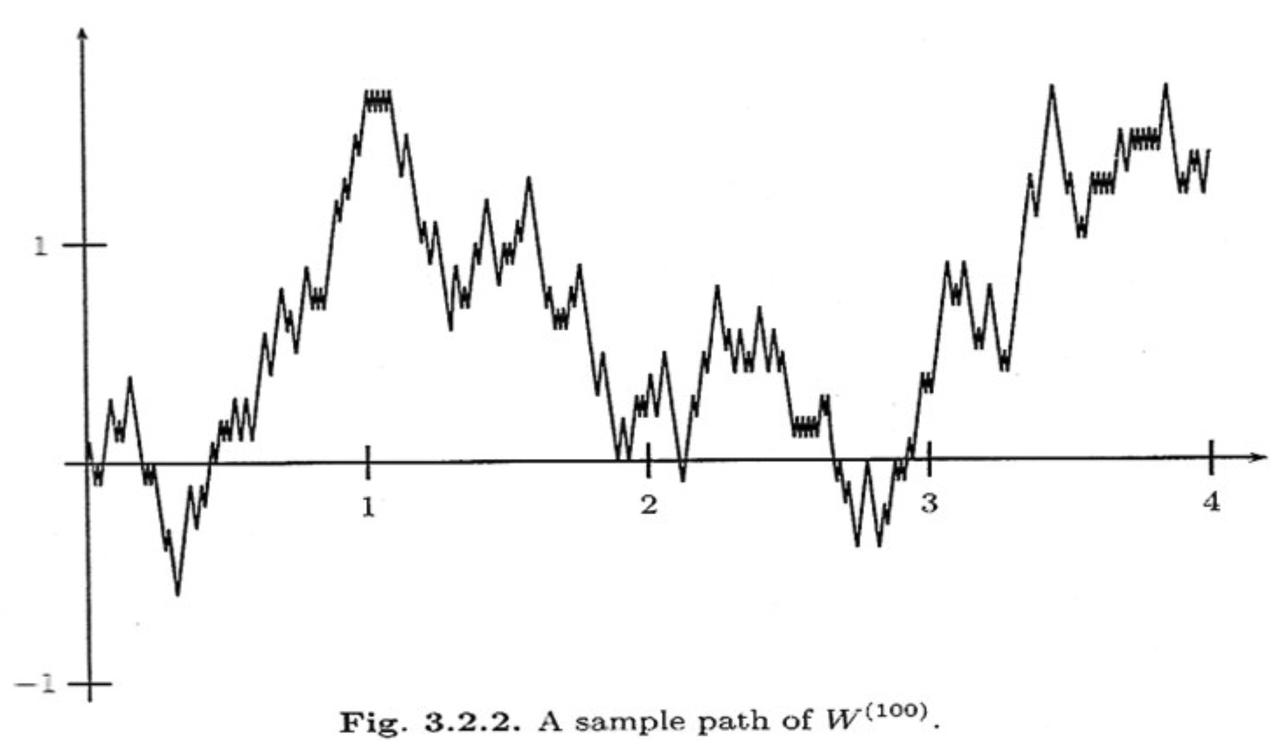
图 2:缩放的对称随机游走(图片来源)
由于这仍然只是一个简单的对称随机游走(假设我们观察的是整数步),因此与例 3 中讨论的性质一致:非重叠增量彼此独立。此外,对于 ,我们有:
这里我们使用了平方根缩放,使得方差仍然以单位时间为增量进行积累。
另一个重要性质被称为二次变差,它是沿某一特定路径计算的(即没有随机性)。对于某一已知路径的缩放对称随机游走过程,我们有:
我们得到的结果与公式 2.14 中的方差一致(当 时),但在概念上它们是不同的。方差是对所有路径的平均,而二次变差是在某条已实现路径上,取所有增量的平方并求和。在 Wiener 过程的特殊情形下,它们结果一致(但对于一般的随机过程并不一定成立)。
最后,正如你所料,我们希望理解当 时,这种缩放的随机游走过程将如何变化。对于固定的 ,我们回顾以下事实:
- (由公式 2.14 设 得出);
- (同上);
- ,其中 是伯努利过程;
- 根据中心极限定理:
其中 是独立同分布的随机变量,且满足一定条件。
我们可以看出,缩放的对称随机游走过程完全满足中心极限定理的条件,因此当 时, 收敛于均值为 、方差为 的正态分布。这正是我们在下一节中用来定义 Wiener 过程的方法。
Wiener 过程定义
我们终于来到了 Wiener 过程的定义,这个过程是前面所述的“缩放对称随机游走”在 时的极限形式。我们将依据这个极限定义的分布性质来定义 Wiener 过程,这些性质大多是从“缩放对称随机游走”中继承而来:
给定概率空间 ,假设存在一个关于 的连续函数,并且也依赖于 ,我们将其记作:
若满足以下条件,则 是一个 Wiener 过程:
- 初始值为零:
- 所有不重叠的增量都是独立的,即对于任意满足 ,有以下增量: 互相独立;
- 每个增量都是正态分布,且具有期望 与方差 。
我们可以看到,Wiener 过程继承了缩放对称随机游走的许多性质,尤其是增量独立与增量服从正态分布。不过,Wiener过程的增量是严格的正态分布,而不是像前面的随机游走那样只是在大 情况下近似正态。
我们可以从物理的角度理解 Wiener 过程:每个 表示一个随机路径,比如悬浮在液体中的粒子的随机运动。每一个时间的无限小片段,粒子都会被随机扰动(且扰动服从正态分布)而改变方向。这正是植物学家 Robert Brown 最早观察到的布朗运动现象的数学模型,后来爱因斯坦等人对其进行了严格的数学建模。
另一种理解方式是“硬币抛掷”:我们可以认为 是一系列无限快发生的硬币抛掷结果——不像之前的模型只在整数时间点发生,而是在每一个无限小的时间片段中发生。这正是取极限的结果。
此时,我们可以对 Wiener 过程在任意时间点 提出我们对随机变量的所有典型问题。下面我们就来看一个简单的例子。
例5:Wiener 过程概率计算
假设我们希望求出 Wiener 过程在 时,其值落在区间 内的概率。
换句话说,我们希望计算如下事件的概率: ,使得
我们知道Wiener过程在区间 上的增量服从: 因此我们只是想求一个正态分布落在特定区间内的概率。根据正态分布密度函数公式:
我们还需要讨论Wiener过程的滤波(filtration)。定义与前面章节相同,但我们要额外强调:未来的增量必须独立于当前的 信息。
正是因为后面我们会将更复杂的自适应过程作为被积函数(integrand),并以Wiener过程作为积分器进行积分,所以这种“未来不可预知性”是合理性的核心。这是为了防止被积过程“看到未来”。
Wiener过程的二次变差(Quadratic Variation)
我们之前在讨论缩放后的对称随机游走(scaled symmetric random walk)时提到,其二次变差随时间线性累积,即在区间 上的总二次变差为 ,且这一结论与分割数 无关。我们将看到,这一现象对于 Wiener 过程也成立。但在此之前,我们先来思考为什么这件事看起来很奇怪。
设函数 定义在区间 上。它在 上的二次变差(quadratic variation)定义为:
其中, 是对区间 的划分,满足: , 且 表示分割的网格大小(mesh),即
这个定义的核心思想和我们之前讨论的类似:对每个小区间取函数值之差的平方,再将所有区间相加。与黎曼积分(Riemannian integrals)定义类似(尽管我们通常不是这样学习的),只不过这里的划分可以是不均匀的,只要网格趋于0即可。
现在我们有了式 (2.18),让我们看看它作用在一个可导函数上时会发生什么。根据均值定理(Mean Value Theorem): 若 在区间 上可导且连续,则存在 ,使得: 。 在此基础上,对有连续导数的函数 ,其二次变差推导如下:
这表明,对于我们日常中遇到的那些具有连续导数的函数,其二次变差为0,即几乎没有实际意义。 但对于 Wiener 过程来说,其路径处处连续却处处不可导,因此我们无法像 (2.19) 那样使用均值定理。
为此我们来看一个更简单的例子:图3 所示的绝对值函数 。
在区间 上,我们可以计算两个端点之间的平均斜率为 。 但在整个区间内,函数 的导数永远不会等于:要么是 ,要么是 ,在 处导数甚至不存在。因此,该函数并没有一处导数值恰好等于 。
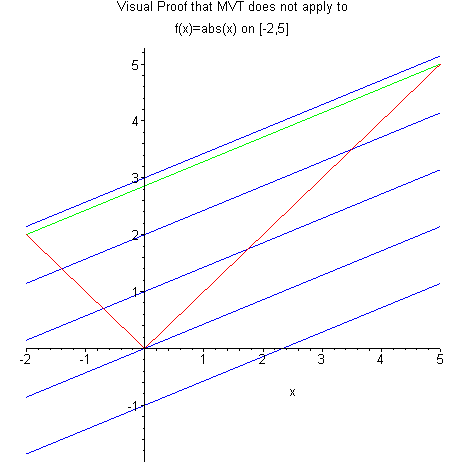
图3:均值定理无法用于不可导函数 (图片来源)
这与我们在缩放对称随机游走中遇到的情况很相似——每两个离散点之间我们都采用线性插值,但无论怎么插值,随着分割数 增加,这种“尖角”行为仍然存在,并最终在极限中被 Wiener 过程继承。
因此我们要面对这样一种函数:处处连续却处处不可导。这正是我们需要随机微积分(Stochastic Calculus)的根本原因之一——否则我们本可以使用熟悉的经典微积分法则。
定理 1
对于Wiener过程 ,其二次变差为 ,对所有 几乎必然成立。
证明
定义如下采样的二次变差(参考公式 2.18):
这个量是一个随机变量,因为它依赖于Wiener过程的特定“结果路径”(回顾下二次变差是相对于某一条实际路径定义的)。
为了证明该定理,我们需要证明,当分割的粒度趋于 0 时,采样的二次变差 。 我们只需证明 。 这意味着,无论路径如何, 都收敛于 。
我们知道Wiener过程的每个增量彼此独立,因此其总和的期望值和方差就是各个增量期望值和方差的总和。
已知(根据Wiener过程定义):
所以我们可以计算:
再由已知结论(正态随机变量四阶矩期望为 3 倍方差)可得:
接着我们来计算单个增量的平方差的方差:
最终我们可以计算 的方差:
由于我们设定 ,即每段长度趋于 0,而个数趋于无穷,那么这个和将趋于 0,所以 。 因此, 几乎必然成立,定理得证。
术语 几乎必然(almost surely)是一个技术术语,意思是“概率为1”。这在处理无穷时是另一个直觉上难以理解的概念。定理并不是说没有具有不同二次变差的路径,而是说这些路径在无穷多个路径中是可以忽略的,因此它们的概率为零。
从更高层次看,这是一个非常深刻的结果:如果你取 Wiener 过程中的任意一条实际路径,对其无限小的平方增量求和,其和几乎必然等于区间的长度。换句话说,Wiener 过程以每单位时间积累一个单位的二次变差。
这可能让人惊讶,因为它可以是任意一条路径。无论“无限快”的硬币掷出的结果如何,平方增量之和总会趋近于区间长度。尽管路径是连续的(但没有连续导数),最终结果非零,这也令人惊讶,如我们上面所讨论的。
我们通常会非正式地写成:
来描述以单位速率积累二次变差。然而,这不应被理解为对每一个无限小增量都成立。请记住, 的每个增量是正态分布的,所以等式左边实际上是一个正态分布变量的平方。我们只有在对大量增量求和时,才会得到定理1的结果(详情见[1])。
我们还可以用这种非正式记号来描述一些相关概念:交叉变差(公式 2.27)和时间变量的二次变差(公式 2.28)分别为:
时间的二次变差可以用上文公式 2.18 中的定义,而交叉变差则是使用两个不同的函数( 和 ),而不是同一个函数。直观地,这两个变差都是0,因为时间增量 在极限中趋近于0,因此这两个变差也随之趋近于0。这可以用与前述二次变差类似的论证更正式地证明(详见[1])。
Wiener 过程的首次到达时间(First Passage Time)
我们在这里插入一个非直观的性质来说明 Wiener 过程:它最终必然会达到某个给定的水平 。
定理 2
对于 ,Wiener 过程达到水平 的首次到达时间 几乎必然是有限的,也就是说,
这基本上说明,Wiener 过程几乎肯定会在某个有限时间 内达到任意一个有限水平 。换句话说,虽然确实存在一些路径使得 Wiener 过程永远不达到这个水平 ,但这些路径的集合是如此微小,以至于它们的概率为 0(即几乎必然不会发生)。处理无穷时确实常常带来一些不直观的结果。
Wiener 过程与白噪声的关系
Wiener 过程可以通过几种等价的方式来刻画,上面给出的定义是其中最常见的一种。另一种常见的定义方式是利用我们在动机部分中提到的白噪声。在这种定义下,Wiener 过程是高斯白噪声的定积分,换句话说,高斯白噪声是 Wiener 过程的导数:
为了理解这个关系为何成立,我们先从 [4] 中定义的随机过程的导数说起:
一个随机过程 ,如果在二次均值意义下可导,其导数为 ,那么它满足:
其中 。
我们可以看到,这个定义与普通微积分中导数的定义非常相似,只是这里我们要求的是期望趋近于 0,并且是一个更弱的平方收敛。我们将在下一节中再次看到这种收敛方式。
从这个定义出发,我们可以计算 导数的期望:
类似地,我们可以对随机过程导数的时间相关性给出一个通用性质的推导:
因此我们可以得出结论,随机过程导数的时间相关性是协方差函数的二阶偏导。接下来我们只需要将其应用到 Wiener 过程上即可。
首先,假设 ,Wiener 过程的时间相关性为(详见这个 StackExchange 答案):
我们若假设 ,也会得到相同的结果,因此:
接下来我们要计算它的二阶偏导数。只要 ,一阶偏导是很容易的(参考这个 StackExchange 答案):
其中 是 Heaviside 阶跃函数。而我们知道,该阶跃函数的导数就是 Dirac δ 函数(即使在间断点处未定义也无妨),因此:
从公式 2.32 和 2.36 可见,这和我们在动机部分的公式 1.4 中对白噪声的定义具有相同的统计特性。由于均值为零,协方差就等于时间相关性,即 。
现在我们只需要再证明其服从正态分布。根据上文定义,Wiener 随机过程的导数为:
由于 Wiener 过程的每个增量都服从正态分布(且相互独立),所以上述导数也是正态分布的,因为两个独立正态变量的差仍然服从正态分布。
因此我们可以得出结论:Wiener 过程的导数是一个均值为零、时间相关性为 Dirac δ 函数的高斯过程,这正是高斯白噪声的标准定义。于是我们便证明了公式 2.29 / 2.30 中所给的关系。
Wiener 过程的重要性
你可能会问(尤其是在阅读下一节之后):为什么我们要如此关注 Wiener 过程?事实上,Wiener 过程是唯一一个具有平稳独立增量的连续过程(当然,是在一个缩放因子和漂移项的自由度下)[5]。我们可以更精确地表述这个结论。
一个随机过程如果满足以下条件,就称其具有独立增量:对于任意 ,增量 与所有满足 的过去值 相互独立。
如果增量的分布不依赖于 或 本身,而仅依赖于差值 ,那么称其具有平稳增量(stationary increments)。
由此我们可以得到一个非常重要的结论:
定理 3
任何具有平稳独立增量的连续实值过程 ,都可以表示为:
其中 为常数。
公式 2.38 定义了广义的 Wiener 过程,它包括了一个可能非零的初始值 ,一个确定性的漂移项 ,以及一个缩放因子 。
这个定理的直觉来源其实就是中心极限定理。对于区间 ,增量 可以看作是许多个无穷小的、独立同分布的子增量之和,也就是说可以看作是若干独立同分布的随机变量之和(它们不一定服从正态分布)。因此,根据中心极限定理,在一些温和的假设下,这个和趋近于正态分布。
具有独立增量的过程在很多实际场景中都会出现。例如:一个宏观粒子在液体中运动,由于与液体分子的随机碰撞产生了随机位移,这种过程很自然地可以用 Wiener 过程建模。又比如,股票价格在非常短的时间内的收益波动基本上与价格本身无关,因此也可以被建模为 Wiener 过程。我们稍后会详细探讨这两个例子。
随机微积分
随机微积分的主要目标之一,就是要让以下这个积分有意义:
其中 和 是两类特殊的随机过程。这引出了几个关键问题:
-
我们从这个随机积分中得到了什么“东西”?
其实很简单,结果依然是一个随机过程。尽管这点一开始可能不太显然,但定义出来后你会发现这是很自然的结论。 -
如何处理积分区间是时间 ,但被积函数和被积变量却是带有时间指标的随机过程这一点?
我们会看到,这个积分的定义在概念上与普通的 Riemann 积分 没有本质不同,但因为所用的是随机过程(比如 Wiener 过程),所以会有一些关键的区别。 -
当被积变量(例如 Wiener 过程)是不可导的时怎么办?尤其是它有非零的二次变差(quadratic variation)时?
这正是随机微积分与普通微积分之间最重要的区别之一。在普通积分中不重要的选择(比如采样点),在随机积分中却会影响结果,从而导致和传统积分操作不同的输出。
我们之前学习的所有内容现在都要派上用场了!我们将用那些概念来严谨地定义公式 3.1。我们先从最简单的情况入手,也就是当 ( X(t) ) 是 Wiener 过程时的积分定义,然后再推广到更广义的 Itô 过程,并引入一个关键结果 —— Itô 引理,它可以看作是随机版本的链式法则,从而帮助我们解决更多有趣的问题。
布朗运动(Brownian Motion)下的随机积分
首先我们从最简单的情况开始,也就是积分器 是Wiener过程(Wiener Process)。对于这个简单的情况,我们可以这样定义积分:
其中 ,而 是分割的最大区间长度,在分割数量趋近于无穷时趋近于 0,类似于标准的黎曼积分。
从宏观上看,公式 (3.2) 与我们平常接触的黎曼积分区别不大。然而,需要注意的是,我们现在积分的是 而不是 ,这会使结果比普通积分更加“波动”。我们可以通过一个小时间步长 来对比一下普通积分和随机积分的近似形式,时间从 开始:
我们可以看出 比 的变化更可预测,因为每一小段的变化只是 。注意 仍然可以是一个随机函数, 也可以是随机的,但它的变化是乘上一个确定性的 。
而相反的, 的变化是 ,这意味着它是一个服从独立正态分布的随机变量(每段Wiener过程增量是独立的,分布为 )。因此像 这样的项变化就非常随机和剧烈,因为增量是独立随机的,而不仅仅是一个 。 这正是我们为什么需要定义一种新的“微积分”的核心直觉之一。
为了确保公式 (3.2) 中的随机积分是良定义的,我们需要满足几个条件,下面简要总结如下:
-
对于采样点 的选择非常关键(这不同于常规积分中采样点的选择不影响结果)。Itô 积分通常使用 ,这种定义在金融领域中更常见;而 Stratonovich 积分使用的是 。 这种定义在物理学中更常见。我们将在本文的大部分讨论中使用 Itô 积分,但稍后会用实例展示两者的区别。
-
被积函数 必须适应于(adapted to)与积分器 相同的过程。这意味着 不能“看到未来”的信息。这在大多数应用中是合理的假设。
-
被积函数需要满足平方可积性条件,也就是: 。
-
理想情况下,我们希望每个采样点的函数值 在取极限时能以概率 1 收敛到 。但这是一个很强的条件,因此我们实际使用较弱的 平方收敛(mean-square convergence) 条件,即:
其中我们定义: 。 也就是说, 是 的分段常值逼近,并且是取区间左端点的值。
例 6:一个用两种方式计算的简单随机积分
我们来计算一个简单的积分,其中被积函数和积分器都是 Wiener过程:
首先,我们采用 Itô 约定,即选取 :
第一项是一个望远镜求和(telescoping sum),具有大量的抵消项:
第二项就是我们在定理 1 中看到的方差项(quadratic variation),它等于时间间隔 。将两者合并,我们得到:
我们会注意到,这个结果几乎看起来像普通微积分中的结果,比如: , 只是多了一个额外项。正如我们上面看到的,这个额外项恰恰是由于 Wiener过程具有非零的二次变差(quadratic variation)而产生的。如果 Wiener过程具有连续可微的路径,那我们就不需要这些关于随机积分的额外处理。
我们现在来看在 Stratonovich 积分定义下,使用符号 表示的积分 是如何处理的。我们使用中点采样 ,定义如下:
我们利用了半样本二次变差等于 这一事实,其证明方法类似于定理 1。
从这里我们可以看出,Stratonovich 积分实际上更符合我们通常的微积分规则,这也是它在某些领域中被使用的原因。然而,在许多领域(如金融)中,它却并不合适。
这是因为被积函数代表的是我们在某一时间区间内所做出的决策: 比如对某种资产的持仓,而我们必须在该区间开始之前就做出决策,而不是在中间某个时刻才决定。就好比你在一天快结束时才决定:“早上我其实应该多买一点这只上涨的股票”——这就太迟了。
布朗运动随机积分的二次变差
让我们来研究一下刚刚定义的随机积分在某条路径上的二次变差(或称为增量平方差的总和),以及一个相关的性质。注意:随机积分的“输出”本身是一个随机过程。
定理 3
由 Wiener过程(记作 ,见公式 3.2)构成的 Itô 积分在时刻 累积的二次变差为:
定理 4(Itô 等距公式)
公式 3.2 中与Wiener过程相关的 Itô 积分满足以下等式:
有几个需要注意的地方。
首先,二次变差是由底层被积函数 缩放的,而不像Wiener过程那样以每单位时间累积单位变差。
其次,我们开始看到 二次变差 和 方差 之间的区别:二次变差是路径相关的,它取决于 在时间 之前所经历的路径。如果 较大,那么累积的二次变差也会较大;反之亦然。而方差是对所有路径进行平均后得到的固定值,在给定分布下它不会因单一路径而变化。
最后,我们借助公式 2.26-2.28 中的非正式微分记号,来直观理解一下二次变差。我们可以将第 3.2 式中的 Itô 积分改写为:
这称为积分形式,而它的微分形式如下:
两者是等价的。
微分形式从直觉上更容易理解。它与上一小节中我们讨论的近似表达(公式 3.4)是吻合的。利用这种微分记号,并结合公式 2.26-2.28 中的非正式规则,我们可以“计算”二次变差如下:
其中我们使用了Wiener过程的二次变差增长速率为 1 单位/时间这一事实(来自定理 1): 。 我们将在后续讨论随机微分方程(SDE)时频繁使用这种微分记号。
Itô 过程与积分
在前面的子小节中,我们只考虑了Wiener过程作为被积函数的情况,但我们希望将其扩展到更一般的一类随机过程,称为 Itô 过程1:
设 是一个带有关联滤过(filtration) 的Wiener过程。Itô 过程是如下形式的随机过程:
其中 是非随机常数,而 和 是适应于滤过 的随机过程。
这个表达式(公式 3.16)也可以写成更自然的(非正式)微分形式:
很大一类的随机过程其实都是 Itô 过程。事实上,任何平方可积并且关于某个Wiener过程所生成的滤过是可测的随机过程,都可以被公式 3.16 表示出来(参见 鞅表示定理(martingale representation theorem))。因此,很多我们在实际中关心的随机过程其实都是 Itô 过程。
使用我们的微分记号,我们可以对公式 3.17 求期望和方差,以获得更深的理解:
在公式 3.18 中, 和 是独立的,这是因为 是适应于 的过程,而 是关于 的“未来”增量。因此,它们之间没有相关性。
这种推理只在 Itô 积分中成立,这是因为在公式 3.2 中我们选取了 (即左端点)来决定积分的采样点。
事实上,这个结果在我们转换为积分符号时依然成立:
所以使用 和 的符号是有意义的:普通的时间积分项贡献于 Itô 过程的均值,而随机积分项贡献于其方差。我们将在下一节看到如何对它们进行实际操作。
最后,和我们之前讨论的其他过程一样,我们也希望知道它的二次变差(quadratic variation)。我们可以用非正式的微分记号来计算二次变差:
这个结果与我们在上面公式 3.19 中使用的计算基本一致(也和方差一样)。实际上,我们得到了和更简单的 Wiener 过程一样的结果,也就是说每单位时间的二次变差累积为 。这是因为交叉变差项(公式 2.27)和时间自身的二次变差项(公式 2.28)都为零,不会影响最终表达式。
最后,让我们看看如何使用非正式的微分记号来计算一个 Itô 过程 的积分:
如我们所见,它只是一个简单的 Wiener 过程随机积分与一个常规时间积分的和。
例 7:一个简单的 Itô 积分
从我们的 Itô 过程开始:
其中 和 是常数。现在,使用该过程作为被积函数,计算一个简单的积分:
其中 是常数。从这里我们可以看出,该过程的均值和方差可以直接计算,因为唯一的随机部分是 : 这是我们直接从公式 3.20/3.21 得到的相同结果。最终结果是一个简单的随机过程,本质上是一个 Wiener 过程,但其均值随时间以速率 增长。
Itô 引理
虽然许多随机过程可以写成 Itô 过程的形式,但我们所研究的过程往往并不符合公式 3.16/3.17 的形式。 一个常见的情形是,我们目标的随机过程 是一个确定性的函数 。 它是一个更简单的 Itô 过程 的函数形式:
在这种情况下,我们希望有一种方法可以将它简化为只包含一个 和一个 项的形式,即公式 3.16/3.17 那种更简单的形式。这个技巧就叫做 Itô 引理(Itô's lemma)。
Itô's引理
设 是如公式 (3.16)/(3.17) 所示的伊藤过程,函数 拥有连续定义的偏导数 , , 对于任意 ,有:
由于 ,上述积分项可以展开为:
非正式证明
将函数 按照泰勒展开式进行展开:
接下来将 替换为 ,并将 替换为,得到:
正如你所见,我们可以将上面公式 3.28 中的随机过程重新写成仅包含一个 项和一个 项的形式(使用微分记号表示)。这可以被看作是全导数链式法则的一种形式,只不过现在由于存在非零的二次变差,我们需要额外包含一个关于 的二阶项。
Itô 引理是一个极其重要的结果,因为随机微积分的大多数应用“不过是在各种情境中反复使用这个公式” [1]。实际上,据我所知,很多随机微积分的入门课程都会跳过大量理论内容,直接进入 Itô 引理的应用,因为这基本就是你最需要掌握的内容。
例 7:Itô 引理
给定 Itô 过程 (如公式 3.16 所定义),我们考虑如下随机过程 :
使用 Itô 引理,我们可以将 重写为微分形式(因为这样更简洁):
这个结果将 表示为一个只包含 和 项的更简单形式。
随机微分方程(Stochastic Differential Equations)
我们使用随机微积分最常见的问题之一是求解随机微分方程(SDE)。与非随机微分方程类似,SDE 出现在许多不同的现象中(我们将在下一节看到一些例子),而且它们通常写起来很自然,但不一定容易求解。
我们从定义开始:
一个随机微分方程具有如下形式:
其中, 和 是已知函数,分别称为漂移项(drift)和扩散项(diffusion)。此外,给定初始条件 ,其中 。问题就是要找出在 时满足上述条件的随机过程 。
请注意, 出现在等式的两边,这使得很难显式地求解。不过一个不错的性质是:在 和 满足一些适当条件的情况下,存在一个唯一的过程 能够满足上述方程。而且你可能也能猜到,对于一维的线性 SDE,我们是可以显式地求解的。
SDE 也会带来和非随机微分方程类似的复杂性,比如非线性、SDE 系统、多维 SDE(伴随多个维纳过程)等等。一般来说,大多数 SDE 并没有显式的闭式解,因此通常需要借助数值方法来求解。
两种常用的数值方法是 蒙特卡洛模拟 和 数值求解偏微分方程(PDE)。
大致来说,蒙特卡洛方法是通过模拟底层过程的多条路径,然后用这些路径来计算相关统计量(例如均值、方差等)。只要模拟路径足够多(以及有足够的时间),你通常就能获得任意精度的结果。
另一种方法是数值求解 PDE。在金融应用中,SDE 可以重写为一个 PDE 问题,然后就可以使用大量成熟的数值方法来求解这些 PDE。不过,这两种方法的详细工作原理超出了本文的范围(也是我目前不打算深入的内容),但网上有大量关于它们的资料。
随机微积分的应用
(注:在本节中,为了简化记号,我们将省略随机过程的显式参数表示。)
Black-Scholes-Merton 期权定价模型
要推导出 Black-Scholes-Merton 模型的完整数学过程相当深入,因此这里仅提供对一些主要概念和直觉的简要概述(紧随参考文献 [6])。如果想要更轻量但直观的解释,可以参考 [6],而详细的数学推导请见 [1]。
股票价格过程
股票价格可能是人们最自然会想到使用随机过程的领域之一。我们可能会尝试直接使用具有常数 和 的 Itô 过程,但这会导致股票价格呈线性增长,而这并不符合实际。投资者通常预期的是 固定的百分比收益,而非固定的线性增长。例如,如果股票预期增长 10%,无论价格是 10 还是 100,都应该按该比例增长。
这自然导致了如下关于股票价格 和常数收益率 的微分方程(这当然是个很强的假设):
也就是说,股票价格的变化 等于当前价格的百分比增长 。对两边同时除以 并积分,可以求得时间 时的解为:
当然,这个简化模型中没有任何随机成分。我们自然会预期,在一定时间内收益率是具有不确定性的。一个(或许)合理的假设是:在较小时间段内,收益的波动性相对于股票价格是相同的。换句话说,无论股票价格是 10 还是 100,我们对其回报的“相对不确定性”是相似的。
引入 Wiener 过程,我们可以将该假设加入公式 4.1 中,得出:
这就形成了一个被称为几何布朗运动(Geometric Brownian Motion, GBM)的随机微分方程。
幸运的是,GBM 具有封闭形式的解。我们可以通过对函数 应用 Itô 引理来推导这个解:
由此可知,在区间 上, 是一个正态分布过程,其均值为 , 方差为 , 即:
这意味着 服从一个 对数正态分布(log-normal distribution),其统计特征如上所述。
Black-Scholes-Merton 微分方程
BSM 模型大概是数量金融中最著名的方程,但它的推导其实非常复杂,需要用到我们之前学习过的所有随机微积分知识。这个模型的核心是 BSM 微分方程,我们接下来将推导并讨论它。
首先要理解的是“无套利”(no arbitrage)条件。对于金融衍生品(例如看涨期权或看跌期权)和其所对应的基础股票来说,其价格不应该允许我们构建一个只买入或卖空这两者的投资组合就可以保证盈利的情形——也就是说,不存在套利机会。在这种理论投资组合中,你可以是“多头”,也就是买入并持有某项金融资产,或者是“空头”,即欠着但并不持有这项资产(这通常是通过借入资产、卖出它、之后再以更低的价格买回来、并归还借入的资产实现的)。理论上的“做空”本质上是买入操作的相反方向:资产价格下跌时你可以获利。
为了构建这样一个无风险或“无套利”的投资组合,我们希望以完全按照资产价格相对变动比例的方式去做多/做空基础股票,同时做空/做多衍生品。这个资产比例只在一个非常短的时间间隔内满足上述条件,并且必须随着市场条件的变化不断进行再平衡。
另一个关键概念是:一旦你构建好了这样一个“无风险”组合,它的回报应该等于“无风险利率”(在那个很短的时间段内保持平衡的前提下)。所谓无风险利率,指的是一种几乎可以确保获得该收益率的资产(例如:储蓄账户、或者更常见的是国债)。在上述几个条件和其他一些理想化假设下(如:股票价格满足我们之前建立的模型、无交易成本、无分红、可以完美做空等),我们就可以建立 BSM 微分方程了。
将上面的想法转化为具体的方程,我们首先假设某只股票的价格服从几何布朗运动,也就是之前的公式 4.3: 该股票上的一个期权,其价格是当前股票价格 和时间 的某个函数 。应用 Itô 引理可以得到: 公式 4.6 和 4.7 描述了:(a)基础股票价格 的微小变动,以及(b)该金融衍生品价格 的微小变动。注意两个方程中的 Wiener 过程是相同的,这是因为 是由 推导出来的(可从 Itô 引理的推导中看出)。
现在我们手上有了股票价格 和期权价格 的随机微分方程。我们的目标是构建一个包含这两种资产的投资组合,使得在某一时间和价格 下,这个组合对股票价格的随机波动不敏感,也就是说不随 的变化而变化。
我们可以通过让两个 SDE 中的随机项(即 项)互相抵消来实现这个目的。由于 项是唯一的随机来源,一旦它被消去,我们就可以得到一个确定性地随时间变化的投资组合表达式。
为了抵消随机项,只需要将方程 4.6 和 4.7 中的 项相等,即可。这样,我们会得到这样一个组合:做空一个衍生品,持有 份的标的资产。换句话说,组合中包含 空头 一个金融衍生品和 多头 股股票。将组合的价值定义为 ,我们有:
对 取微分,并应用 Itô 引理,同时代入方程 4.6 和 4.7:
根据设定(我们的假设条件), 是一个在时间 上“无风险”的组合,其价值是确定性地随时间变化的。无套利假设意味着这个组合的收益必须等于无风险利率 。如果组合收益高于 ,你可以借入无风险资金构建这个组合并套利;如果组合收益低于 ,你可以做空这个组合、购买无风险资产,同样套利。
由此我们可以推断,在这个完美平衡的投资组合持续的无穷小时间内, 的收益应等于无风险利率。利用公式 4.9,我们可以构建一个随机微分方程:
公式 4.10 定义了 Black-Scholes-Merton 微分方程。请注意,这实际上是一个关于 的确定性微分方程,因为我们已经将随机的 Wiener 过程项消去了,而且 和 是给定的变量,而 是我们要求解的函数。
该方程的解取决于施加在 上的边界条件)。例如,对于欧式看涨和看跌期权,其行权价格为 ,到期时间为 ,边界条件如下:
换句话说,当期权合约到期时,它的价值恰好是股票价格与执行价格之间的差额,若该差额为负则为 0(看跌期权则相反)。
解这个带边界条件的微分方程,就得到了最著名的 BSM 公式(更多细节点这里)。这里我们不展开介绍公式的具体形式,因为这不是本文的重点。但需要注意的是,BSM 公式有封闭形式解,这在金融建模中是一大优势。相比之下,许多更复杂的量化金融模型都不具有封闭解,甚至会超出 Itô 过程的范围(例如 跳跃过程(Jump Process))。这些模型通常需要使用近似解法(3.4 节会进一步讨论)。
Langevin 方程
Langevin 方程 是一个著名的随机微分方程,用于描述一个系统在受到确定性力和波动性力共同作用下的演化过程。最初的 Langevin 方程是在随机微积分被正式发展之前就提出的,其背景是研究一个粒子在流体中看似随机运动的行为,即所谓的 布朗运动。由于 Wiener 过程与布朗运动密切相关,它们有时可以互换使用来描述这一底层的随机过程。
许多人都曾为布朗运动的发现做出贡献(包括爱因斯坦),但与之相关的随机微分方程是由 Langevin 于 1908 年推导出来的,因此以他命名。有趣的是,Langevin 并未以数学家的严谨标准来处理他的随机微分方程,这反而催生了“随机分析”这一研究领域,致力于解决他的方法中存在的一些问题。
在本节中,我将简要介绍 Langevin 方程在布朗运动背景下的形式,并略去许多在物理课上通常会做的详细分析。此外,我将使用 Itô 微积分来处理它,这并不是 Langevin 最初采用的方法,也不是传统的方法。最后,我还会简要提到它在金融领域中的一个应用。
4.2.1 布朗运动与 Langevin 方程
原始的 Langevin 方程描述的是,一个(通常较大)粒子在流体中由于与流体分子发生碰撞而产生的随机运动:
其中, 表示粒子的质量, 是粒子的速度, 是加速度(速度对时间的导数), 是白噪声项,它具有零均值和平坦的频谱(也就是我们在第 2.5 节中讨论过的那种白噪声)。
我们可以使用 牛顿第二定律 来理解这个方程:物体所受的合力等于其质量乘以加速度( )。 左边是合力,右边是质量乘以加速度。在这个 Langevin 方程中,右边的力由两个部分组成:(a) 一个与速度成正比的 阻力(想象类似于空气阻力),表示为 ; (b) 一个表示流体中小分子随机碰撞影响的噪声项 。
这个建模有点奇怪,因为我们把微观层面的阻力项(如粒子受到的黏性阻力)和看似宏观平均的噪声项混合在了一起,因此我们需要更多解释。
噪声项 实际上是一种近似。理论上,在任意时间点上都有具体的分子与我们研究的粒子碰撞。那么我们为什么还要使用 这个噪声项呢?除了数学上简化推导之外,更重要的理由是:在小时间间隔内,这个噪声项很好地近似了粒子所受的平均随机力。这是因为我们现实中的观测仪器并不是无限精确的,只能测量有限时间内的平均值,而这些观测在统计上与公式 4.13 中的白噪声项非常相似。
因此,虽然 Langevin 方程并不是完美的物理模型,但它在描述这种物理现象时已经是非常不错的近似(而且也适用于其他很多具有类似结构的系统,只需对基本方程稍作调整)。
有趣的是,当 Langevin 最初写出他的方程时,噪声项实际上并没有被严格地定义(也就是说,并不具有数学上的严谨性)。然而,随着随机微积分的发展,我们可以将其写成一个等价的随机微分方程,这个方程通常被称为 Ornstein-Uhlenbeck 过程,形式如下:
其中, 和 是常数,并假设 表示为 。
顺便提一句,从技术上讲,Wiener 过程在数学上是处处不可导的,因此 并没有精确的数学意义。这也是为什么我们很少以这种形式来表示它,而是采用公式 4.14 的微分形式。
公式 4.14 的复杂之处在于,我们的目标过程 同时出现在微分项和非微分项中——这正是随机微分方程的特点。不过由于这是一个相对简单的 SDE,我们可以用类似于常微分方程的技巧,再结合 Itô 引理来计算其解。
不深入探讨背后的全部推理,我们从函数 开始,写下它的微分形式和类似于我们在推导 Itô 引理时的泰勒展开式:
这展示了我们所讨论的随机微分方程的一般解。我们可以通过计算它的均值和方差来刻画这个随机过程。首先,我们利用一个事实,即 Itô 积对确定性被积函数来说是正态分布的,因此方程 (4.15) 中的第二项的期望为 0,于是(假设初始速度 是非随机的):
这表明平均速度随时间衰减得非常快。接下来我们可以使用 Itô 等距定理(前文定理 4)来计算方差:
由平均值与方差的结果,加上我们知道被积函数是关于 的(且 是正态分布的),我们可以推断该随机过程是一个经过缩放和平移的 Wiener 过程:
同样,我们可以通过对速度 关于时间积分来计算位移 :
我们不会展开最后一个时间积分,但你可以参考这个 StackExchange 答案 进行计算,其中说明它的均值为零。因此,平均位移最终收敛到 。 有关该过程的物理背景,可参见维基百科上的 这篇文章。
总结
我又一次掉进了兔子洞!在我意识到之前,我已经在这个主题上越陷越深。
从很多方面来说,自己学习其实挺不错的,因为你可以随心所欲地探索。
不过说实话,当我开始写这篇文章时,我完全没料到会是这样一趟旅程。
我没想到自己会不得不深入了解测度论概率(这原本从来不是我的优先事项),更没想到随机微积分背后的数学直觉理解竟然需要这么多技术细节(而不是只是符号操作)。
不管怎样,我很高兴自己认真钻研了一番,但我也会很高兴能回到一些更标准的机器学习话题上。
下次见!
参考文献
- Wikipedia: Stochastic Processes, Adapted Stochastic Process
- [1] Steven E. Shreve, Stochastic Calculus for Finance II: Continuous Time Models, Springer, 2004.
- [2] Michael Kozdron, Introduction to Stochastic Processes Notes, Stats 862, University of Regina, 2006.
- [3] Introduction to Stochastic Differential Equations, Harvard, 2007.
- [4] Maria Sandsten, Differentiation of stationary stochastic processes, 2020.
- [5] George Lowther, Continuous Processes with Independent Increments
- [6] John C. Hull, Options, Futures, and Other Derivatives, Pearson, 2018.
附录 A:Bernoulli 过程的事件空间与概率测度
正如前面提到的,伯努利过程的样本空间是所有正反面结果的无限序列:
关于这个样本空间的第一件事是,它是不可数的,这基本上意味着它的“大小”比自然数还大。处理无穷集合往往违反直觉,但常见的“无穷”类型主要有两种:一种与自然数具有相同的势,另一种与实数集合具有相同的势。我们的样本空间属于后者。康托尔最初的对角线论证其实就是利用了这种样本空间的一个变体(使用的是 ),而该证明在逻辑上相当直观。
总之,这使问题变得更复杂,因为我们在面对无穷时的直觉常常失效,尤其是在处理实数势的集合时。
(本节构造借自 [1],该参考文献虽然晦涩但涵盖了本文所有主题。)
接下来我们将为伯努利过程构造事件空间(σ-代数)和概率测度。我们将采用迭代的方式构造。首先定义 且, 对应的(平凡)事件空间为:
注意到 是一个 -代数。 接下来定义两个集合:
然后设置直观的概率测度定义 ,, 即第一次抛掷为正面(H)的概率是 ,否则为 。由于这两个集合互为补集,即 。 因此我们获得了另一个 -代数:
我们可以将这个过程扩展到前两次抛掷。定义如下集合:
类似地,我们可以按预期方式扩展概率测度: ,,,。 接下来我们需要进行一些分析。如果我们列举出由上述事件的补集或并集构造的所有可能集合,会发现一共可以构造出 16 个不同的集合。对于每一个集合,我们都可以使用以下方式来计算其概率测度:使用上述的定义或者使用规则 ,或者若 互不相交,则 。
这 16 个集合定义了下一个 -代数:
我们可以继续这一过程,为所有由有限次抛硬币构造的事件定义其概率及对应的 -代数。我们称这个集合为 ,它包含了所有可以通过有限次硬币投掷,以及对这些事件取补集和并集所构造的集合。
这个 恰好就是 Bernoulli 过程的 -代数,并且我们已经为其中的每个事件构造好了对应的概率测度。
现在我们本可以就此打住,但不妨再看看当我们处理“无限”时会出现哪些违反直觉的现象。这一定义隐含地包含了一些我们并未显式定义的序列,例如,全是正面的序列: 但我们可以看到,这个序列包含在以下集合的交集中: 进一步地,我们有: 这意味着“全为正面”这个序列的概率为: 。 这揭示了一个重要但违反直觉的结果:样本空间中所有“无限长的序列”的概率都是 0。重要的是,这并不意味着它们永远不会发生,而是说它们发生的概率“无限小”。 相反的事件,“至少有一个反面”的序列,其概率是 1。 数学家称这种概率为 1 的事件为“几乎必然”(almost surely)。所以任何一个无限次抛硬币的序列,几乎必然会至少出现一个反面。对于有限的事件空间,“一定发生”(surely)与“几乎必然”(almost surely)是没有区别的。
这个定义还包含了某些不能简单定义的序列集合,例如:
其中 表示在前 次中出现正面的次数。这可以通过我们在事件空间中定义的集合的可数次并与交来隐式构造。详见文献 [1] 的示例 1.1.4。
最后,尽管看起来我们好像已经定义了样本空间的所有子集,但实际上还是存在某些序列,它们不属于 。 不过,构造这样一个集合非常困难(别问我怎么做 :p)。